
Wie funktioniert AlphaZero's Gehirn?
In meinem ersten Artikel über AlphaZero habe ich erklärt wie AlphaZero Varianten berechnet. In diesem Artikel werde ich erklären, wie es AlphaZero schafft, sich selbst Schach beizubringen.
Einige Details werde ich beschönigen müssen, aber ihr werdet hoffentlich trotzdem eine Vorstellung davon bekommen, wie AlphaZerlo´s Gehirn funktioniert.
Das Innenleben von AlphaZero
Gehen wir gleich in die Vollen. AlphaZero lernt mit einem neuronalen Netzwerk, das man sich so vorstellen kann:
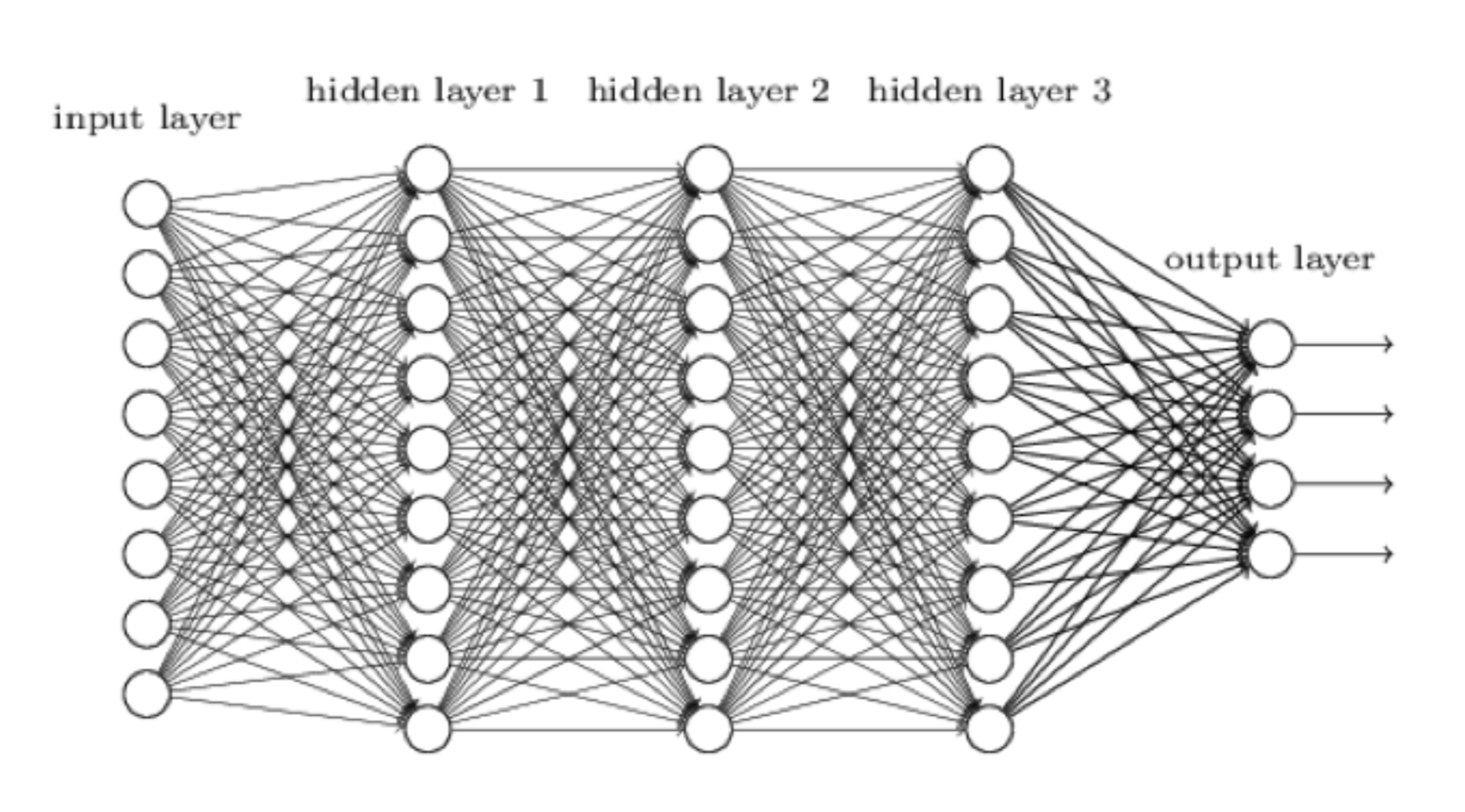 Ein neuronales Netzwerk ist unser Versuch, ein Computersystem mehr wie ein menschliches Gehirn, und weniger ein Computer denken zu lassen. Die Eingabe, d. h. die aktuelle Stellung auf dem Schachbrett, kommt auf der linken Seite herein. Es wird von der ersten Schicht von Neuronen verarbeitet, von denen jede ihre Berechnung an jedes Neuron rechts von ihm sendet, bis die äußerste rechte Neuronenschicht ihre Berechnung abschließt und die endgültige Ausgabe erzeugt. Bei AlphaZero besteht diese Ausgabe aus zwei Teilen:
Ein neuronales Netzwerk ist unser Versuch, ein Computersystem mehr wie ein menschliches Gehirn, und weniger ein Computer denken zu lassen. Die Eingabe, d. h. die aktuelle Stellung auf dem Schachbrett, kommt auf der linken Seite herein. Es wird von der ersten Schicht von Neuronen verarbeitet, von denen jede ihre Berechnung an jedes Neuron rechts von ihm sendet, bis die äußerste rechte Neuronenschicht ihre Berechnung abschließt und die endgültige Ausgabe erzeugt. Bei AlphaZero besteht diese Ausgabe aus zwei Teilen:
- Eine Bewertung der Ausgangsstellung.
- Eine Bewertung aller möglichen Züge in dieser Stellung.
Hey, AlphaZero klingt ja hier schon fast wie ein echter Schachspieler: “Weiß steht hier etwas besser, und Lg5 oder h4 sehen ganz vernünftig aus!”

Diese Neuronen müssen also clevere Kerlchen sein, oder? Ein Neuron ist eigentlich eine sehr einfache Verarbeitungseinheit (es kann sich in der Software oder der Hardware befinden), die eine Anzahl von Eingaben akzeptiert, jede mit einer bestimmten Wichtung multipliziert, die Antworten summiert und dann eine sogenannte Aktivierungsfunktion anwendet die eine Ausgabe ergibt, typischerweise im Bereich von 0 bis 1. Eine Sache, die zu beachten ist, dass das, was ein Neuron ausgibt, potenziell von jedem anderen Neuron im Netzwerk vor ihm abhängt, was es dem Netzwerk ermöglicht, Feinheiten zu erfassen. Wie im Schach, wo der rochierte König von Weiß sicher steht. Nach h3 ändert sich aber die Bewertung, da Schwarz ja die g-Linie mit g7-g5-g4 öffnen kann.
Basierend auf den Daten, die über AlphaGo Zero (AlphaZeros Go-spielenden Vorgänger) veröffentlicht wurden, hat das neuronale Netzwerk von AlphaZero wahrscheinlich bis zu 80 Schichten und Hunderttausende von Neuronen. Zählt man das zusammen, erkennt man, dass dies Hunderte von Millionen von Wichtungen ergibt. Wichtungen sind wichtig, weil das Trainieren des Netzwerks (auch Lernen genannt) eine Frage der Gewichtswerte ist, damit das Netzwerk Schach gut spielt. Stellt euch vor, es gibt ein Neuron, das während des Trainings die Rolle der Beurteilung der Königssicherheit übernommen hat. Es nimmt den Input von allen vorausgehenden Neuronen im Netzwerk und lernt, welche Wichtungen man ihnen gibt. Wenn AlphaZero Matt gesetzt wird, nachdem alle Bauern vor seinem König bewegt wurden, wird es seine Wichtung anpassen, um die Möglichkeit zu verringern, diesen Fehler erneut zu machen.
Wie AlphaZero lernt
AlphaZero beginnt als absoluter Novize. Ein großes neuronales Netzwerk mit zufälligen Gewichtungen. Es wurde entwickelt, um zu lernen, wie man Zwei-Spieler-Spiele mit abwechselnden Zügen spielt, weiß aber absolut nichts über irgendein bestimmtes Spiel. Ähnlich wie wir mit der enormen Fähigkeit geboren wurden eine Sprache zu lernen, aber keinerlei Kenntnis von irgendeiner Sprache haben.
Der erste Schritt bestand darin, AlphaZero die Schachregeln beizubringen. Dies bedeutet, dass es nun zufällige, aber zumindest legale Züge spielen konnte. Der natürliche nächste Schritt schien zu sein, ihm Meisterpartien, von denen man lernen kann zu zeigen. Diese Technik nennt man beaufsichtigtes Lernen. Dies hätte jedoch dazu geführt, dass AlphaZero nur gelernt hätte, wie fehlerhaft wir Menschen Schach spielen. Daher entschied sich das Google-Team für einen ehrgeizigeren Ansatz: Verstärkendes Lernen. Dies bedeutet, dass AlphaZero Millionen von Partien gegen sich selbst spielen musste. Nach jeder Partiel hat es einige seiner Gewichtungen optimiert und entschlüsselt, was gut funktioniert hat und was nicht.
Als dieser Lernprozess begann, konnte AlphaZero nur zufällige Züge spielen und alles, was es wusste, war, dass das Schachmatt das Ziel des Spiels ist. Stellt euch vor, ihr versucht, Prinzipien wie die Kontrolle des Zentrums oder den Minoritätsangriff einfach nur aus der Tatsache, dass ein Spieler den anderen am Ende der Partie Matt gesetzt hat, zu erlernen! Während dieser Lernphase wurde AlphaZeros Fortschritt gemessen, indem man Zweitausend-Turniere mit Stockfish und den vorherigen Versionen von sich selbst spielte. Es scheint unglaublich, aber AlphaZero hat nach vier Stunden Selbstspiel genug über Schach gelernt, um Stockfish's Bewertung zu übertreffen, obwohl es nur etwa 0,1 Prozent der von Stockfish berechneten Varianten berechnet hat.
Dies klingt ziemlich überwältigend, aber ich möchte daran erinnern, dass die Menschheit Schach auf ähnliche Weise gelernt hat. Seit Jahrhunderten spielen Millionen von Menschen Schach und wir nutzen unsere Gehirne, um mehr über dieses Spiel zu lernen. Wie ein riesiger Multiprozessor-Computer auf Kohlenstoffbasis. Wir haben durch viele Niederlagen gelernt, dass es wichtig ist, im Zentrum zu spielen, Türme auf offene Linien zu ziehen, Bauernketten an der Basis anzugreifen, usw. Das musste auch AlphaZero tun. Es wäre faszinierend, seine 44 Millionen Partien gegen sich selbst zu sehen. Ich frage mich, in welcher von denen der Minoritätsangriff entdeckt wurde.
Wie AlphaZero Schach spielt
Bisher haben wir gesehen, wie AlphaZero sein neuronales Netzwerk trainiert, damit es eine gegebene Stellung auswerten und beurteilen kann, welche Züge wahrscheinlich gut sind (ohne etwas zu berechnen).
Hier ist noch ein bisschen mehr Terminologie: Der Teil des Netzwerks, der Stellungen bewertet, wird Wertschöpfungsnetzwerk genannt, während der Teil "Züge-Vorschlager" als Richtliniennetzwerk bezeichnet wird. Jetzt sehen wir uns an, wie diese Netzwerke AlphaZero dabei helfen, Schach zu spielen.
Erinnern wir uns zuerst daran, dass das große Problem im Schach die Explosion von Varianten ist. Bereits nach dem 2. Zug nach der Eröffnung sind etwa 150.000 verschiedene Stellungen möglich und diese Zahl wächst exponentiell mit jedem Zug weiter an. AlphaZero reduziert die Anzahl der zu betrachtenden Varianten, indem nur die vom Richtliniennetzwerk empfohlenen Varianten berücksichtigt werden. Es nutzt auch sein Wertschöpfungsnetzwerk, um Varianten, deren Bewertung zeigt, dass sie eindeutig entschieden sind (gewonnen / verloren) nicht weiter zu berechnen.
Laut des Richtliniennetzwerks gibt es in jeder Stellung drei vernünftige Züge. Bei AlphaZero´s sehr bescheidener Rechenleistung von 80.000 Stellungen pro Sekunde konnte es in einer Minute ungefähr sieben volle Züge vorausberechnen. Wenn man dies mit der Anwendung seiner instinktiven Bewertung durch sein Wertesystem für die Stellungen am Ende der Varianten verbindet, wird einem klar, welche mächtige Schachspielmaschine AlphaZero ist.
Die Hardware, auf der AlphaZero läuft
Es überrascht sicher niemanden, dass das neuronale Netzwerk von AlphaZero auf einer speziellen Hardware läuft, nämlich den Tensor Processing Units (TPU) von Google. AlphaZero verwendet 5.000 TPUs der ersten Generation, um die Partien gegen sich selbst zu generieren, mit denen das Netzwerk trainiert wird, und 64 TPUs der zweiten Generation für das eigentliche Training. Das ist eine gigantische Menge Rechenleistung. Um tatsächlich Schach zu spielen, wurden nur vier TPUs verwendet.
Warum hat Google die anderen 5.060 TPUs nicht auch verwendet? Wahrscheinlich um zu zeigen, dass AlphaZero keine massive Hardware benötigt, um effektiv zu funktionieren.

Google’s Tensor Processing Units (TPU).
Wenn ein neuronales Netzwerk Werte zwischen seinen Schichten propagiert, wird jeder Input für jedes Neuron mit einem bestimmten Gewicht multipliziert, was im Wesentlichen eine Matrixmultiplikation ist (denken Sie daran, dass das von der Schule stammt?). Das TPU wurde von Google ausschließlich zum Trainieren und Betreiben neuronaler Netze entwickelt und ist daher auf die Matrixmultiplikation spezialisiert. Eine Matrixmultiplikationsoperation, die eine normale CPU in Ihrem Laptop eine lange Reihe von Berechnungen nehmen würde, kann eine TPU in einem einzelnen Taktzyklus erledigen (und die erste Generation TPU macht 700 Millionen Zyklen pro Sekunde). Denken Sie an eine Maschine in einer Fabrik, die 100 Flaschen Soda auf einmal verschließen kann, während eine arme Seele sie nacheinander anzieht.
AlphaZero gegen Stockfish
Nach nur vier Stunden Training hatte AlphaZero dann die Bewertung von Stockfish übertroffen. Es wurde fünf weitere Stunden trainiert, aber in dieser Zeit gab es keine oder nur geringe Verbesserungen. Ja, das ist an sich interessant: Die Entwickler lieferten hierzu keine weiteren Informationen, die eine Interpretation ermöglichen würde. Dann trat AlphaZero zu einem 100 Partien Duell gegen Stockfish an, welches AlphaZero mit 64-36, bei keiner einzigen Niederlage, gewann. Das hört sich zwar wie eine absolute Demontage an, entspricht aber tatsächlich nur einem Unterschied von 100 Punkten in der Elo-Bewertung. Es wurde viel über die Fairness und die Chancengleichheit bei diesem Duell geschrieben. Stockfish wurde sein Eröffnungsbuch verweigert, welches aber für Schachprogramme typisch ist. Stockfish verwendete 64 Threads, was darauf hindeutet, dass es auf einem sehr leistungsfähigen PC lief, aber es verwendete nur eine bescheidene Hash-Größe von 1 GB. Demgegenüber verfügte AlphaZero über 5.064 TPU, nutzte aber nur vier von diesen für die Partien.
Viele Leute haben deshalb vorgeschlagen, einen fairen Vergleichskampf zwischen den beiden Programmen zu arrangieren, aber das ist wegen der radikal unterschiedlichen Hardware, auf die die beiden Programme angewiesen sind, nicht wirklich möglich. Ein Rennen zwischen einer Person und einem Pferd würde nicht als "fair" angesehen werden, wenn das Pferd nur auf 2 Beinen laufen dürfte.
Was man aber keinesfalls leugenen kann und was absolut erstaunlich ist, ist die Tatsache, dass AlphaZeros Kombination aus Hardware und Software innerhalb von vier Stunden lernen und Stellungen besser bewerten konnte, als das hochgelobte Stockfisch-Programm.
Und wer jetzt immer noch an die Größe von Stockfish's Hash-Tabelle denkt, dem sei gesagt, dass die Leistung von AlphaZero wäre nur um eine Nuance weniger erstaunlich gewesen wäre, wenn das Programm nur knapp gegen Stockfish verloren hätte.
Ich will AlphaZero auf meinem Laptop!
Oh nein, das wollt ihr nicht! AlphaZero trainiert neuronale Netze. Was ihr wollt, ist das neuronale Netzwerk, das AlphaZero trainiert hat, um Schach zu lernen. Genauso wie ihr wollt, dass sich ein Arzt um euren Schnupfen kümmert und nicht, dass er medizinische Forschungsarbeit leistet. Dieses neuronale Netzwerk wurde auf die Festplatte überspielt, während den TPUs, die es trainierten, schon lange andere Aufgaben zugewiesen wurden. Wäre die Netzwerkstruktur und die Gewichtungen veröffentlicht worden, wäre es zumindest theoretisch möglich, AlphaZeros Schachspiel-Netzwerk auf einem Laptop neu zu erstellen, aber seine Leistung würde nicht dem entsprechen, was mit Googles spezieller Hardware erreicht wurde.
Aber wie Nahe würde das Programm dann an AlphaZero herankommen? Lass uns mal eine sehr grobe Berechnung anstellen. Der Teil eures Computers, der für die von AlphaZero durchgeführten Berechnungen am besten geeignet ist, ist die GPU oder Grafikverarbeitungseinheit. Das mag merkwürdig erscheinen, aber bei der Grafik dreht sich alles um die Matrixmultiplikation, was auch ein neuronales Netzwerk benötigt. Google schätzt, dass seine TPU ungefähr 20 Mal schneller ist als eine moderne GPU, sodass die 4-TPU-Maschine, die Stockfish besiegt hat, ungefähr 80 Mal mehr Leistung als ein normaler PC hat. Zumindest momentan ist dieses Programm also für Heimanwender irrelevant.
Im Bereich der künstlichen Intelligenz findet gerade eine Revolution statt, bei der neuronale Netze eingesetzt werden, um Probleme anzugehen, die zuvor für eine computergestützte Lösung als zu komplex angesehen wurden. AlphaZeros universeller Ansatz ermöglichte es ihm, sich selbst besser zu verstehen und Schach besser zu verstehen (und nicht nur Varianten zu berechnen), als es jeder schachspezifische Ansatz vermocht hätte. Oh, und das gilt auch für Go und Shogi, also Brettspiele mit höherer Rechenkomplexität als Schach. Es ist sehr unwahrscheinlich, dass Google daran interessiert ist, das Schachprojekt weiter voranzutreiben - man wird sich auf anspruchsvollere und lohnendere Probleme konzentrieren.
Und was bedeutet das alles jetzt für das Schach, wie wir es kennen? Es ist ein gigantischer Schritt, dass sich ein Computer Schach auf solch hohem Niveau selbst beibringen kann und sich dabei mehr auf menschenähnliches Lernen als auf traditionelle Brute-Force-Berechnungen verlässt. Dies verursacht eine Delle in unserer Vorstellung von der menschlichen Überlegenheit. Es wird zweifellos einen Einfluss darauf haben, wie sich Schach-Engines in Zukunft entwickeln werden, und wir müssen widerwillig akzeptieren, dass das aufschlussreichste Schach von Maschinen gespielt wird.
Die Hardware, auf der AlphaZero läuft, wird der Öffentlichkeit also in absehbarer Zeit nicht zur Verfügung stehen. Vergesst aber nicht, dass, als der speziell angefertigte Deep Thought (der Vorgänger von Deep Blue) Bent Larsen 1988 schlug, sich seine Schöpfer kaum vorstellten konnten, dass nur wenige Jahre später jedes Schulkind eine solche Rechenleistung in seiner Hosentasche mit sich herumtragen würde.
Watch This Space - wie sie sagen.

