
¿Qué hay en el cerebro de AlphaZero?
En la primera entrega de este artículo hablé de cómo AlphaZero calcula las variantes. En esta segunda entrega hablaré de cómo aprende a jugar al ajedrez de forma autónoma.
Tendré que dar algunos datos sin entrar en demasiado detalle, pero espero que sea suficiente para ayudarte a entender mejor cómo funciona Alphazero.
Dentro de AlphaZero
Vayamos directamente al meollo del asunto. El aprendizaje de AlphaZero sucede mediante una red neural que puede visualizarse así:
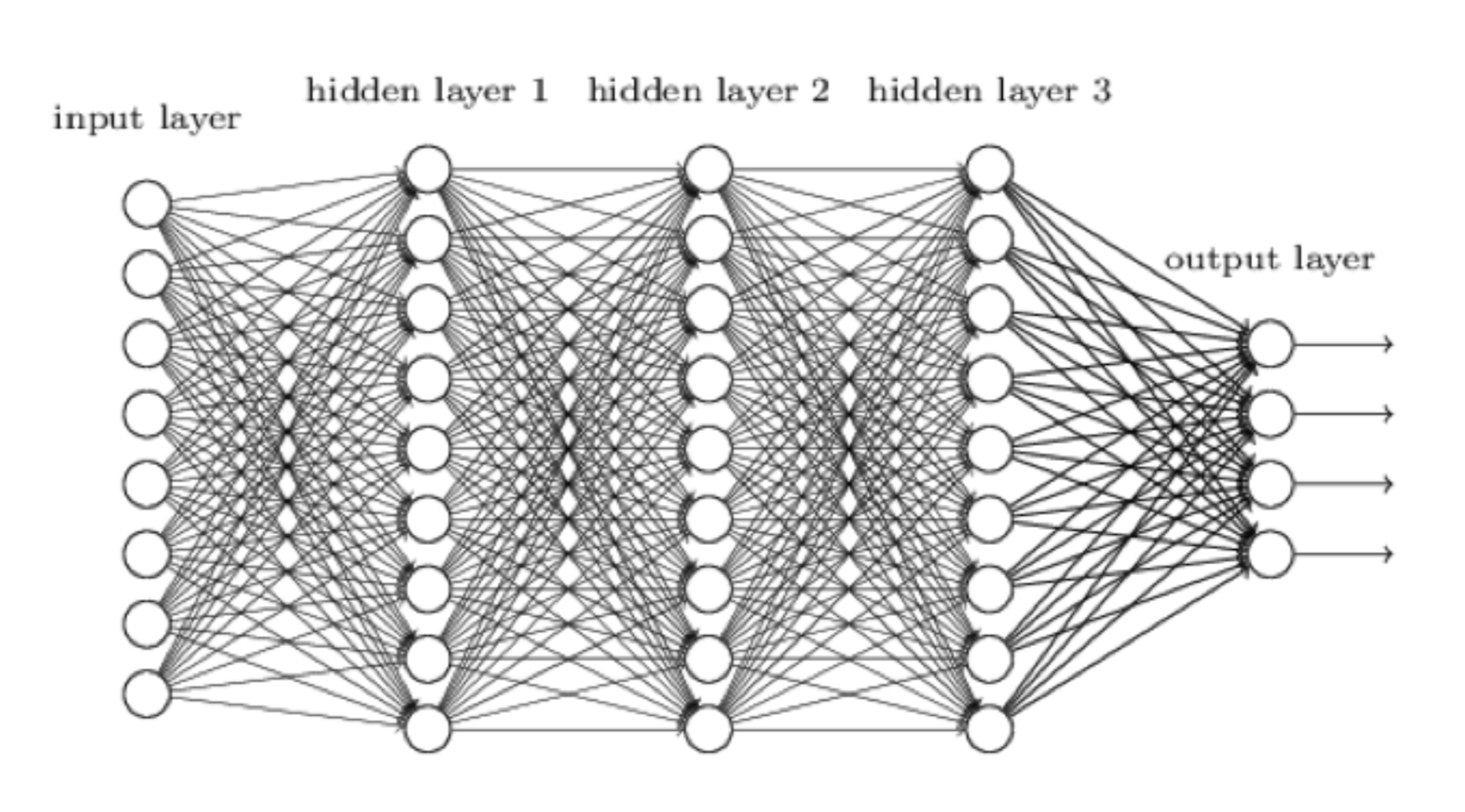
Representación de la red neural del sistema de aprendizaje y juego de AlphaZero
Una red neural es nuestro intento de hacer un sistema informático más similar al cerebro humano y menos similar a un ordenador. El input (o "aporte"), por ej., la posición actual sobre el tablero, entra por la izquierda. Lo procesa la primera capa de neuronas, cada una de las cuales envía su output (o "resultado") a cada neurona en la siguiente capa, y así hasta que la capa de neuronas del extremo derecho hacen su labor y producen el resultado final. En AlphaZero, este resultado tiene dos partes:
- Una evaluación de la posición de ajedrez que se le había planteado.
- Una evaluación de cada jugada legal en la posición.
Oye, AlphaZero ya suena como un ajedrecista: "¡Las blancas están un poco mejor aquí y Ag5 ó h4 parecen buenas jugadas!"

Pues estas neuronas deben de ser muy inteligentes, ¿no? En realidad, una neurona es una unidad de procesamiento muy simple (puede estar en el software o en el hardware) que acepta una serie de aportaciones, multiplica cada una por una cantidad de peso, suma las respuestas y luego aplica una función de activación que da un resultado, típicamente en el rango de 0 a 1. Una cosa a observar es que el resultado de una neurona puede depender de todas las neuronas que hay en la red antes que ella, lo cual permite a la red captar sutilezas, como en el ajedrez donde el rey enrocado de las blancas está a salvo, pero tras h3 la evaluación cambia, pues las negras pueden abrir la columna de "g" con g7-g5-g4.
En base a los datos publicados por AlphaGo Zero (el antecesor de AlphaZero Go), la red neural de AlphaZero probablemente tiene hasta 80 capas y cientos de miles de neuronas. Echa cálculos y entenderás que eso significa cientos de millones de pesos. Los pesos son importantes porque entrenar a la red (también conocido como "aprendizaje") es una cuestión de dar a los pesos valores para que la red juegue bien al ajedrez. Imagina que hay una neurona que durante el aprendizaje ha asumido el rol de evaluar la seguridad del rey. Recoge el aporte del resto de neuronas anteriores en la red y aprende qué pesos darle. Si a AlphaZero le dan mate tras mover todos sus peones delante de su rey, ajustará sus pesos para reducir la posibilidad de volver a cometer este error.
Cómo aprende AlphaZero
AlphaZero comienza como un lienzo en blanco, una gran red neural con pesos aleatorios. Ha sido diseñado para aprender a jugar juegos de dos jugadores con movimientos alternos, pero no sabe nada de ningún juego en concreto, del mismo modo que nosotros nacemos con una inmensa capacidad de aprender lenguaje, pero sin el conocimiento de ninguna lengua en particular.
El primer paso fue el de dar a AlphaZero las reglas del ajedrez. Así, ahora puede jugar movimientos aleatorios, pero al menos legales. El siguiente paso natural parecería ser el darle partidas de maestros de las que aprender, una técnica llamada aprendizaje supervisado. Sin embargo, esto habría dado como resultado que AlphaZero solo aprendería a jugar ajedrez como lo hacemos nosotros, con sus errores, así que el equipo de Google optó por usar un enfoque más ambicioso llamado aprendizaje de refuerzo. Esto significa que dejaron que AlphaZero jugara millones de partidas contra sí mismo. Tras cada partida, ajustaba algunos de sus pesos para tratar de codificar (es decir, memorizar), qué funcionó y qué no.
Cuando AlphaZero emprendió este proceso de aprendizaje, solo podía hacer jugadas arbitrarias y todo lo que sabía era que el objetivo del juego es dar jaque mate. ¡Imagina intentar aprender conceptos como el control del centro o el ataque de minorías solo a partir de quién dio jaque mate a quién al final de la partida! Durante este período de aprendizaje, el progreso de AlphaZero se midió jugando torneos de un segundo por movimiento contra Stockfish y contra las versiones previas de sí mismo. Parece realmente increíble pero, tras cuatro horas jugando contra sí mismo, AlphaZero había aprendido suficiente ajedrez para superar el ELO de Stockfish, y eso examinando solo alrededor del 0,1% de posiciones que examinaba Stockfish.
Aunque esto resulta bastante impactante, recuerda que la humanidad aprendió a jugar al ajedrez de forma similar. Durante siglos, millones de humanos han jugado al ajedrez, usando su cerebro para aprender sobre este juego como un ordenador gigante con multiprocesador. Aprendimos por las malas a jugar en el centro, a poner las torres en columnas abiertas, a atacar cadenas de peones en la base, etc. Es lo mismo que tuvo que hacer AlphaZero. Sería fascinante ver sus 44 millones de partidas contra sí mismo. Me pregunto en cuál descubrió el ataque de minorías.
Cómo juega al ajedrez AlphaZero
Hasta ahora hemos visto cómo AlphaZero entrena a su red neural para que esta evalúe una posición de ajedrez y valore qué movimientos pueden ser buenos (sin calcular nada).
Aquí tienes algo más de terminología: la parte de la red que evalúa las posiciones se llama red de valores, mientras que la parte que recomienda movimientos se llama red de políticas. Ahora veamos cómo estas redes ayudan a AlphaZero a jugar al ajedrez.
Recuerda que el gran problema en el ajedrez es la explosión de variantes. Solo calcular dos movimientos por delante de la posición de apertura requiere contemplar unas 150.000 posiciones, y esta cifra crece exponencialmente cada movimiento que profundizas. AlphaZero reduce el número de variantes que mira considerando solo los movimientos que le recomienda su red de políticas. También usa su red de valores para dejar de contemplar líneas cuya evaluación sugiere que están claramente decididas (ganada/perdida).
Digamos que hay una media de tres movimientos posibles decentes disponibles según la red de políticas. Entonces, en la modesta cantidad de 80.000 posiciones por segundo que emplea AlphaZero, podría mirar unos siete movimientos completos por delante en un minuto. Si unimos a esto la aplicación de su evaluación instintiva, provista por su red de valores, a las posiciones que hay al final de las variantes que contempla, tenemos en efecto una máquina de jugar al ajedrez muy potente.
El hardware con el que funciona AlphaZero
No es sorprendente que la red neural de AlphaZero opere con un hardware especializado: las unidades de procesamiento por tensores (TPU) de Google. AlphaZero usa 5.000 TPUs de primera generación para generar partidas de juego autónomo, las cuales se usan para entrenar a la red, y 64 TPUs de segunda generación para realizar el entrenamiento como tal. Esta es una cantidad enorme de energía informática. Para jugar al ajedrez solo se usaron cuatro TPUs.
¿Por qué no usó Google también las otras 5.060 TPUs? Probablemente para mostrar que AlphaZero no necesita un hardware enorme para operar de forma eficaz.

Las unidades de procesamiento por tensores (TPU) de Google.
A medida que una red neural propaga valores entre sus capas, cada aporte a cada neurona se multiplica por cierto peso en una multiplicación de matrices. Google diseñó la TPU solo para entrenar y operar redes neurales, así que se especializa en multiplicación de matrices. Una operación de multiplicación de matrices requeriría a la CPU normal de tu ordenador una larga serie de cálculos, mientras que una TPU lo puede hacer en un simple ciclo de reloj (y la TPU de primera generación hace 700 millones de ciclos por segundo). Piensa en una máquina en una fábrica que puede poner tapones a 100 botellas de refresco a la vez frente a una pobre persona que los pone uno por uno.
AlphaZero vs Stockfish
Tras cuatro horas de entrenamiento, el ELO de AlphaZero había superado al de Stockfish. Se entrenó durante otras cinco horas pero, en este tiempo, logró poca o ninguna mejoría (sí, esto es interesante de por sí, pero los investigadores no dieron más información que facilite la interpretación). En ese momento, los dos jugaron un match de 100 partidas con un minuto por movimiento, el cual AlphaZero ganó 64-36 sin sufrir derrotas. Esto parece una buena paliza, pero de hecho corresponde a una diferencia de solo 100 puntos de ELO. Se ha hablado mucho de si este match fue justo. A Stockfish no se le dio su libro de aperturas, el cual es típico en matches entre ordenadores. Stockfish usó 64 hilos, lo cual sugiere que operaba desde un PC muy potente, pero solo usó una función hash de 1 GB. Frente a eso, AlphaZero tenía 5.064 TPUs a su disposición, pero solo usó cuatro en el match.
Muchos han propuesto cómo llevar a cabo un match justo entre ambos, pero esto no es realmente posible, pues utilizan hardwares totalmente distintos. Una carrera entre una persona y un caballo no se volvería "justa" si solo se permitiera el uso de dos piernas/patas.
Lo que es innegable e increíble es que la combinación del hardware y el software de AlphaZero pudiera aprender en cuatro horas a evaluar posiciones y movimientos de ajedrez mejor que el refinadísimo Stockfish.
Si sigues pensando en el tamaño de la función hash de Stockfish, te estás perdiendo la clave de lo que ha sucedido. Pongámoslo así: El logro de AlphaZero solo habría sido una pizca menos impresionante si hubiera perdido contra Stockfish por un resultado similar.
¡Quiero AlphaZero en mi ordenador!
¡Oh no, no lo quieres! AlphaZero entrena redes neurales. Lo que tú quieres es la red neural a la que AlphaZero enseñó a jugar ajedrez. Del mismo modo que quieres un doctor para que mire tu dedo hinchado, no una universidad de medicina. Sin duda, esta red neural habrá sido pasada a un disco mientras las TPUs que la entrenaron desarrollan otras tareas. Si se publicaran la estructura y los pesos de la red, sería posible, al menos teóricamente, recrear la red de juego de ajedrez de AlphaZero en un portátil, pero su rendimiento no estaría al nivel de lo que puede lograrse con el hardware especializado de Google.
¿Cuánto se aproximaría? Hagamos unas sumas muy por encima. La parte de tu ordenador que es más apropiada para los cálculos que realiza AlphaZero es la GPU (la unidad de procesamiento de gráficos). Eso puede parecer raro, pero los gráficos son todo multiplicación de matrices, que es justo lo que necesita una red neural. Google calcula que su TPU es unas 20 veces más rápida que una GPU moderna, por lo que la máquina de 4 TPUs que venció a Stockfish tiene una potencia al menos 80 veces superior a la de un PC normal. Así que, por el momento, no está al alcance del usuario común.
En el campo de la inteligencia artificial está teniendo lugar una revolución en la que las redes neurales se usan para abordar problemas que antes se consideraban demasiado complejos para un enfoque computacional. El enfoque de finalidad general de AlphaZero le ha permitido enseñarse a sí mismo a entender el ajedrez (no solo calcular variantes) mucho mejor de lo que ha sido capaz ningún enfoque específico del ajedrez. Ah, y también lo logró en el Go y en el Shogi, que son juegos de mesa con una complejidad computacional muy superior a la del ajedrez. Es muy improbable que a Google le interese continuar con el proyecto de ajedrez, pues pondrá sus objetivos en problemas más complicados e importantes.
¿Qué significa esto entonces para el ajedrez tal y como lo conocemos? Es un paso gigante que un ordenador pueda enseñarse de forma autodidacta a jugar al ajedrez a un nivel tan alto basándose en un aprendizaje similar al humano en lugar del tradicional cálculo de la fuerza bruta. Esto hace mella en nuestra noción de la supremacía humana. Indudablemente tendrá un impacto sobre la evolución de los módulos de ajedrez en el futuro y quizá tengamos que aceptar, a nuestro pesar, que el ajedrez más profundo lo juegan las máquinas.
El hardware con el que opera AlphaZero no estará disponible para el público aficionado al ajedrez en el futuro próximo, pero no olvidemos que cuando Deep Thought (el antecesor de Deep Blue) venció a Bent Larsen en 1988, sus creadores no podían imaginar que los alumnos de escuela del futuro llevarían ese tipo de potencia informática en sus bolsillos.
Seguiremos informando...


