
Comment AlphaZero apprend-il les échecs ?
Le processus d'apprentissage d'AlphaZero est, dans une certaine mesure, similaire à celui des humains. Un nouvel article de DeepMind, comprenant une contribution du 14e champion du monde d'échecs Vladimir Kramnik, fournit des preuves solides de l'existence de concepts compréhensibles par les humains dans le réseau d'AlphaZero, même si ce dernier n'a jamais vu la moindre partie d'échecs humaine.
Comment AlphaZero apprend-il les échecs ? Pourquoi joue-t-il certains coups ? Quelles valeurs donne-t-il à des concepts tels que la sécurité du roi ou l'activité ? Comment apprend-il les ouvertures, et en quoi cela diffère-t-il de la façon dont les humains ont développé la théorie ?
Des questions comme celles-ci sont abordées dans un nouvel article fascinant de DeepMind, intitulé Acquisition of Chess Knowledge in AlphaZero. Il a été rédigé par Thomas McGrath, Andrei Kapishnikov, Nenad Tomasev, Adam Pearce, Demis Hassabis, Been Kim et Ulrich Paquet, en collaboration avec Kramnik. Il s'agit de la deuxième coopération entre DeepMind et Kramnik, après leurs recherches de l'année passée lorsqu'ils ont utilisé AlphaZero pour explorer la conception de différentes variantes d'échecs, avec de nouvelles règles.
Encodage des connaissances conceptuelles humaines
Dans leur dernier article, les chercheurs ont essayé une méthode d'encodage des connaissances conceptuelles humaines, afin de déterminer dans quelle mesure le réseau AlphaZero représente les concepts échiquéens humains. Des exemples de tels concepts sont la paire de fou, le (dés)équilibre matériel, l'activité ou la sécurité du roi. Ces concepts ont en commun d'être des fonctions pré-spécifiées qui encapsulent un élément particulier de connaissance spécifique.
Certains de ces concepts ont été repris de la fonction d'évaluation de Stockfish 8, tels que le matériel, le déséquilibre, l'activité, la sécurité du roi, les menaces, les pions passés et l'espace. Stockfish 8 les utilise comme des sous-fonctions donnant des scores individuels qui conduisent à une évaluation "globale" , elle-même exportée comme une valeur continue, telle que "0.25" (un léger avantage pour les blancs) ou "-1.48" (un gros avantage pour les noirs). Notez que des versions plus récentes de Stockfish ont développé des réseaux neuronaux de type Alpha-Zéro mais n'ont pas été utilisées pour cet article.
Le troisième type de concepts englobe des caractéristiques plus spécifiques de niveau inférieur, telles que l'existence de fourchettes, de clouages ou la contestation de colonnes, ainsi qu'une série de caractéristiques concernant la structure de pions.
Après avoir établi ce large éventail de concepts humains, l'étape suivante pour les chercheurs a consisté à essayer de les trouver dans le réseau d'AlphaZero, pour lequel ils ont utilisé un modèle de régression linéaire clairsemé. Après cela, ils ont commencé à visualiser l'apprentissage des concepts humains à l'aide de ce qu'ils appellent des graphiques "quoi-quand-où" : quel concept est appris, quand dans le temps de formation, où dans le réseau.
Selon les chercheurs, AlphaZero développe effectivement des représentations étroitement liées à un certain nombre de concepts humains au cours de la formation, notamment l'évaluation précise de la position, les coups potentiels et leurs conséquences, et les caractéristiques spécifiques de la position.
Un résultat intéressant concerne le déséquilibre matériel. Comme l'a démontré le livre primé de Matthew Sadler et Natasha Regan, Game Changer : AlphaZero's Groundbreaking Chess Strategies and the Promise of AI (New In Chess, 2019), AlphaZero semble considérer le déséquilibre matériel différemment de Stockfish 8. L'article donne des preuves empiriques que c'est le cas à son plus haut niveau : AlphaZero " suit " initialement l'évaluation du matériel de Stockfish 8 au cours de son apprentissage, avant de s'en détourner à un moment donné.
Valeur des pièces & matériel
L'étape suivante pour les chercheurs a été de relier les concepts humains à la fonction de valeur d'AlphaZero. L'un des premiers concepts qu'ils ont examinés était la valeur des pièces, un concept qu'un débutant apprend en commençant à jouer aux échecs. Les valeurs classiques sont neuf pour une dame, cinq pour une tour, trois pour le fou et le cavalier, et un pour un pion. La figure de gauche ci-dessous (tirée de l'article) montre l'évolution du poids des pièces pendant l'entraînement d'AlphaZero, les valeurs des pièces convergeant vers les valeurs communément acceptées.
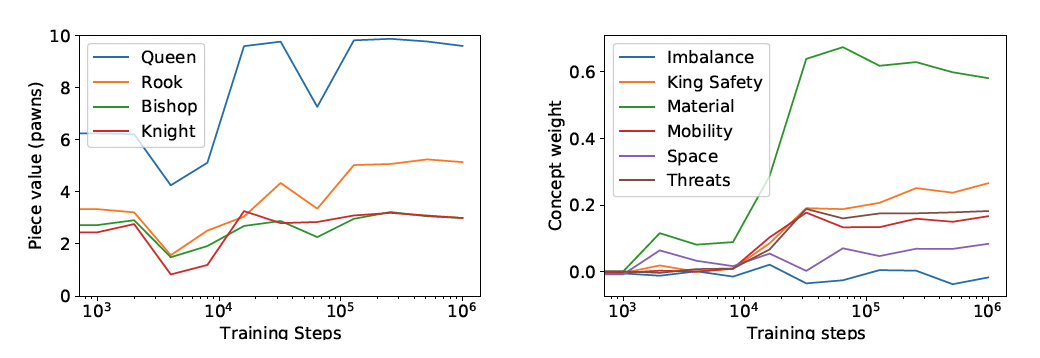
L'image de droite montre que pendant l'entraînement d'AlphaZero, le matériel devient de plus en plus important dans les premières étapes de l'apprentissage des échecs (conformément à l'apprentissage humain) mais il plafonne à un certain point, les valeurs de concepts plus subtils tels que la mobilité et la sécurité du roi deviennent plus importantes alors que l'importance du matériel diminue réellement.
Entrainement d'AlphaZero Vs. Connaissance humaine sur l'histoire
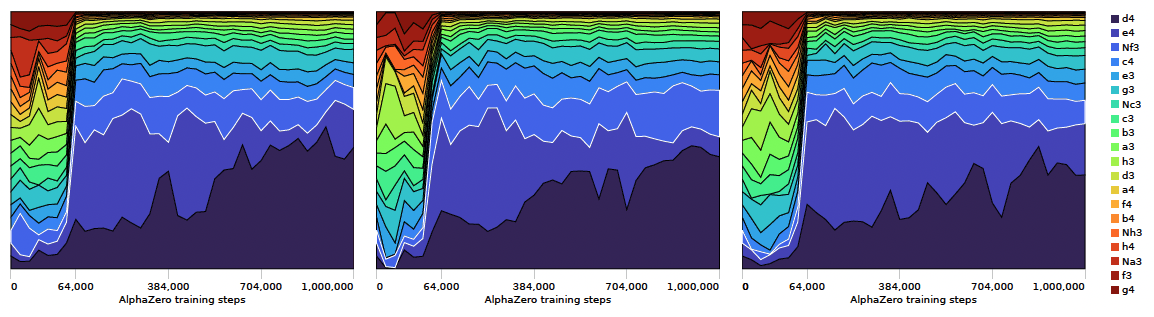
Une autre partie du document est consacrée à la comparaison entre l'entraînement d'AlphaZero et la progression des connaissances humaines au cours de l'histoire. Les chercheurs soulignent qu'il existe une différence marquée entre la progression des préférences de coups d'AlphaZero à travers l'histoire de ses étapes d'entraînement, et ce que l'on sait de la progression de la compréhension humaine des échecs depuis le 15ème siècle :
AlphaZero commence avec un livre d'ouvertures uniforme, lui permettant d'explorer toutes les options de manière égale, et réduit largement les options plausibles au fil du temps. Les parties humaines enregistrées au cours des cinq derniers siècles indiquent un modèle opposé : une préférence initiale écrasante pour 1.e4, avec une expansion des options plausibles au fil du temps.
Les chercheurs comparent les parties qu'AlphaZero joue contre lui-même avec un large échantillon tiré de la méga-base de données de ChessBase, en commençant par les parties de l'année 1475 jusqu'au 21ème siècle.
Au départ, les humains jouaient presque exclusivement 1.e4, mais 1.d4 était légèrement plus populaire au début du 20e siècle, bientôt suivi par la popularité croissante de systèmes plus flexibles comme 1.c4 et 1.Cf3. AlphaZero, quant à lui, essaie un large éventail de coups d'ouverture au début de sa formation avant de commencer à valoriser les coups "principaux".
La variante Berlin de la Ruy Lopez
Un exemple plus spécifique concerne la variante Berlin de la Ruy Lopez (le coup 3...Cf6 après 1.e4 e5 2.Cf3 Cc6 3.Fb5), qui n'est devenu populaire au top niveau qu'au début du 21ème siècle, après que Kramnik l'ait utilisé avec succès dans son match de Championnat du Monde contre Garry Kasparov en 2000. Avant cela, elle était considérée comme quelque peu passive et légèrement suérieure pour les blancs, le coup 3...a6 étant préférable.
Les chercheurs écrivent :
Si l'on regarde en arrière, il a fallu un certain temps à la théorie humaine des ouvertures pour apprécier pleinement les avantages de la défense Berlin et pour établir des moyens efficaces de jouer avec les noirs dans cette position. D'autre part, AlphaZero développe une préférence pour cette ligne de jeu assez rapidement, après avoir maîtrisé les concepts de base du jeu. Ceci met déjà en évidence une différence notable dans l'évolution des ouvertures entre les humains et la machine.
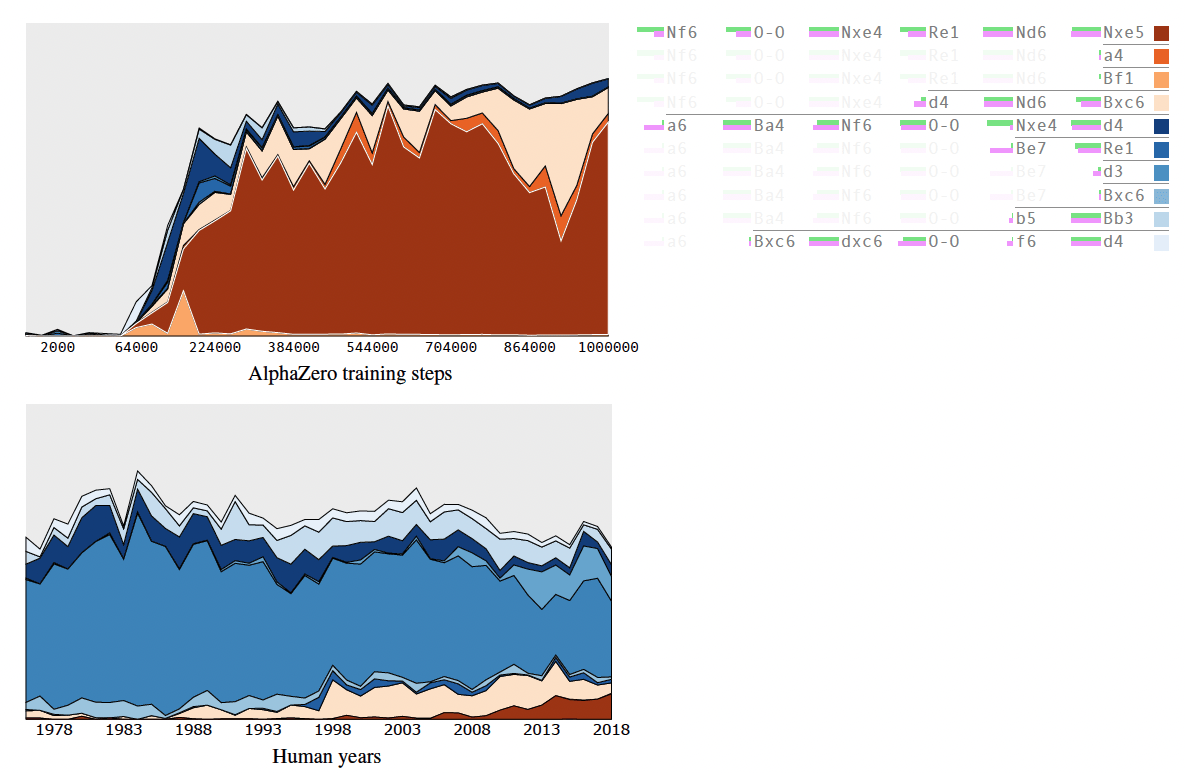
Remarquablement, lorsque différentes versions d'AlphaZero sont formées à partir de zéro, la moitié d'entre elles préfèrent fortement 3... a6, tandis que l'autre moitié préfère fortement 3... Cf6 ! C'est intéressant car cela signifie qu'il n'y a pas de bon joueur d'échecs "unique". Le tableau suivant montre les préférences de quatre réseaux neuronaux d'AlphaZero différents :
| AZ version 1 | AZ version 2 | AZ version 3 | AZ version 4 | |
| 3… Cf6 | 5.50% | 92.80% | 88.90% | 7.70% |
| 3… a6 | 89.20% | 2.00% | 4.60% | 85.80% |
| 3… Fc5 | 0.70% | 0.80% | 1.30% | 1.30% |
Les préférences du réseau AlphaZero après 1. e4 e5 2. Cf3 Cc6 3. Fb5, pour quatre cycles d'entraînement différents du système (quatre versions différentes d'AlphaZero). L'antériorité est donnée après un million d'étapes d'entraînement. Parfois AlphaZero converge pour devenir un joueur qui préfère 3... a6, et parfois AlphaZero converge pour devenir un joueur qui préfère répondre avec 3... Cf6.
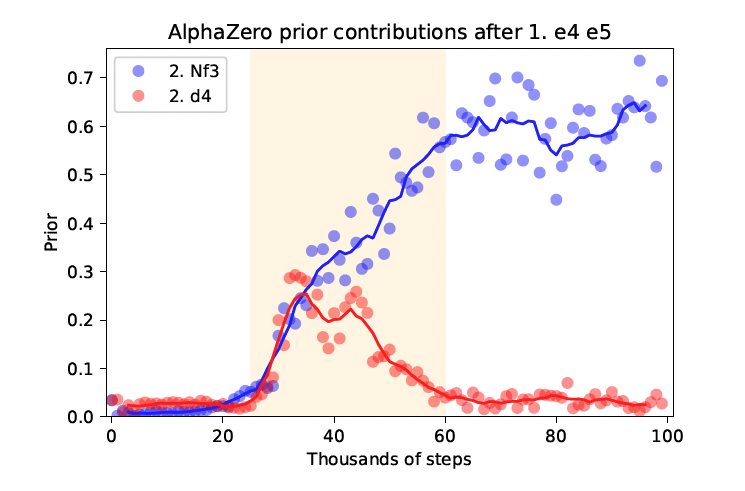
Dans la même veine, AlphaZero développe sa propre "théorie" des ouvertures pour un éventail beaucoup plus large au cours de sa formation. À un moment donné, 1.d4 et 1.e4 sont découverts comme étant de bons coups de départ et sont rapidement adoptés. De même, la suite préférée d'AlphaZero après 1.e4 e5 est déterminée dans une autre courte fenêtre temporelle. La figure ci-dessous illustre comment 2.d4 et 2.Cf3 sont rapidement appris comme des coups raisonnables pour les blancs, mais 2.d4 est ensuite abandonné presque aussi rapidement en faveur de 2.Cf3 comme réponse standard.
L'évaluation qualitative de Kramnik
La contribution de Kramnik au document est une évaluation qualitative, comme une tentative d'identifier les thèmes et les différences dans le style de jeu d'AlphaZero à différents stades de sa formation. Le 14ème champion du monde a reçu des échantillons de parties à quatre stades différents à examiner.
Selon Kramnik, au début de sa formation, AlphaZero a "une compréhension grossière de la valeur du matériel et ne parvient pas à évaluer correctement le matériel dans des positions complexes. Cela conduit à des séquences d'échange potentiellement indésirables, et finalement à des parties perdues pour raisons matérielles". Dans la deuxième phase, AlphaZero semble avoir "une solide compréhension de la valeur matérielle, ce qui lui permet de tirer parti de la faiblesse de l'évaluation matérielle" de la première version.
Dans la troisième étape, Kramnik estime qu'AlphaZero a une meilleure compréhension de la sécurité du roi dans les positions déséquilibrées. Cela se manifeste par le fait que la deuxième version "sous-estime potentiellement les attaques et les sacrifices à long terme de la troisième version, ainsi que la deuxième version surestime ses propres attaques, ce qui entraîne des positions perdantes".
Dans sa quatrième étape de l'entraînement, AlphaZero a une "compréhension beaucoup plus profonde" des attaques qui réussiront et de celles qui échoueront. Kramnik remarque qu'il accepte parfois les sacrifices joués par la "troisième version", procède à une bonne défense, garde l'avantage matériel, et finit par gagner.
Un autre point soulevé par Kramnik, qui ressemble à la façon dont les humains apprennent les échecs, est que les compétences tactiques semblent précéder les compétences positionnelles lors de l'apprentissage d'AlphaZero. En générant des parties autonomes sur des ensembles d'ouvertures distincts (par exemple, le Berlin ou le Gambit Dame refusé dans l'ensemble "positionnel" et la Najdorf et l'Est-Indienne dans l'ensemble "tactique"), les chercheurs parviennent à fournir des preuves circonstancielles mais notent que des travaux supplémentaires sont nécessaires pour comprendre l'ordre dans lequel les compétences sont acquises.

Implications en dehors des échecs
Pendant longtemps, on a cru que les systèmes d'apprentissage automatique apprenaient des représentations ininterprétables qui n'avaient que peu de choses en commun avec la compréhension humaine du domaine sur lequel ils étaient formés. En d'autres termes, la façon dont l'IA s'enseigne et ce qu'elle apprend sont pour la plupart du charabia pour les humains.
Dans leur dernier article, les chercheurs ont fourni des preuves solides de l'existence de concepts compréhensibles par l'homme dans un système d'IA qui n'a pas été exposé à des données générées par l'homme. Le réseau d'AlphaZero montre l'utilisation de concepts humains, même si AlphaZero n'a jamais vu une partie d'échecs humaine.
Cela pourrait avoir des implications en dehors du monde des échecs. Les chercheurs concluent :
Le fait que l'on puisse trouver des concepts humains même dans un système surhumain entraîné par l'autodidaxie élargit l'éventail des systèmes dans lesquels nous devrions nous attendre à trouver des concepts compréhensibles par l'homme. Nous pensons que la capacité de trouver des concepts compréhensibles par l'homme dans le réseau AZ indique qu'un examen plus approfondi en révélera davantage.
Le co-auteur Nenad Tomasev a commenté à Chess.com que pour lui personnellement, il était vraiment curieux de considérer s'il existe une telle chose comme une progression "naturelle" de la théorie des échecs :
Même dans le contexte humain - si nous devions "recommencer" l'histoire, remonter dans le temps - la théorie des échecs aurait-elle évolué de la même manière ? Il y avait un certain nombre d'écoles de pensée importantes en termes de compréhension globale des principes des échecs et des positions de milieu de partie : l'importance du dynamisme par rapport à la structure, les attaques matérielles par rapport aux attaques sacrificielles, le déséquilibre matériel, l'importance de l'espace par rapport à l'école hypermoderne qui invite à l'extension excessive afin de contre-attaquer, etc. Cela a également influencé les ouvertures qui ont été jouées. En regardant cette progression, ce qui reste incertain est de savoir si cela se produirait de la même manière à nouveau. Peut-être que certains éléments de la connaissance échiquéenne et certaines perspectives sont simplement plus faciles et plus naturelles à saisir et à formuler pour l'esprit humain ? Peut-être que le processus d'affinage et d'expansion de ces connaissances a une trajectoire linéaire, ou pas ? Nous ne pouvons pas vraiment recommencer l'histoire, donc nous ne pouvons que spéculer sur quelle pourrait être la réponse.
Cependant, en ce qui concerne AlphaZero, nous pouvons le réentraîner de nombreuses fois et comparer les résultats à ce que nous avons observé précédemment dans le jeu humain. Nous pouvons donc utiliser AlphaZero comme une boîte de Petri pour cette question, en examinant comment il acquiert des connaissances sur le jeu. Il s'avère qu'il existe à la fois des similitudes et des dissemblances dans la façon dont il construit sa compréhension du jeu par rapport à l'histoire humaine. De plus, bien qu'il y ait un certain niveau de stabilité (les résultats concordent entre les différents entraînements), il n'est en aucun cas absolu (parfois, la progression de l'entraînement semble un peu différente, et différentes lignes d'ouverture finissent par être préférées).
Il ne s'agit en aucun cas d'une réponse définitive à ce qui est, pour moi personnellement, une question fascinante. Il y a encore beaucoup à réfléchir. Cependant, nous espérons que nos résultats offrent une perspective intéressante et nous permettent de commencer à réfléchir un peu plus profondément à la façon dont nous apprenons, grandissons, nous améliorons - à la nature même de l'intelligence et à la façon dont elle passe d'une ardoise vierge à ce qui est une compréhension profonde d'un domaine très complexe comme les échecs.
Kramnik a commenté pour Chess.com :
"Il y a deux choses principales que nous pouvons essayer de découvrir avec ce travail. La première est : comment AlphaZero apprend-il les échecs, comment s'améliore-t-il ? C'est en fait très important. Si nous parvenons un jour à le comprendre complètement, nous pourrons peut-être l'interpréter dans le processus d'apprentissage humain.
Deuxièmement, je pense qu'il est tout à fait fascinant de découvrir qu'il existe certains schémas qu'AlphaZero trouve significatifs, qui n'ont en fait que peu de sens pour les humains. C'est mon impression. C'est en fait un sujet à approfondir, en fait, je pense qu'il pourrait facilement être avéré que nous manquons certains schémas très importants aux échecs, parce qu'après tout, AlphaZero est si fort que s'il utilise ces schémas, je suppose qu'ils ont un sens. C'est en fait aussi un sujet très intéressant et fascinant à comprendre, si peut-être notre façon d'apprendre les échecs, de s'améliorer aux échecs, est en fait assez limitée. Nous pouvons l'étendre un peu avec l'aide d'AlphaZero, en comprenant comment il voit les échecs."

Peter Doggers joined a chess club a month before turning 15 and still plays for it. He used to be an active tournament player and holds two IM norms. Peter has a Master of Arts degree in Dutch Language & Literature. He briefly worked at New in Chess, then as a Dutch teacher and then in a project for improving safety and security in Amsterdam schools. Between 2007 and 2013 Peter was running ChessVibes, a major source for chess news and videos acquired by Chess.com in October 2013. As our Director News & Events, Peter writes many of our news reports. In the summer of 2022, The Guardian’s Leonard Barden described him as “widely regarded as the world’s best chess journalist.”
Peter's first book The Chess Revolution is out now!
Company Contact and News Accreditation:
Email: [email protected] FOR SUPPORT PLEASE USE chess.com/support!
Phone: 1 (800) 318-2827
Address: 877 E 1200 S #970397, Orem, UT 84097

